
Redline Face-Off: Experienced Attorneys vs. Frontier AI
Disclaimer: Based on a single test and my personal judgment; not a definitive measure of overall model performance.

“What is the best AI tool for contract redlining?”
This is the question I hear most often when speaking with legal leaders. So when I learned that the newly released GPT-5.4 could produce Word-based redlines, I decided to test it immediately.
The Test
To see how frontier models compare with seasoned attorneys, I used an unpublished contract redline benchmark curated by The Atticus Project.
The task: Produce a redline of three most heavily negotiated clauses—Warranty Disclaimer, Limitation of Liability, and Indemnification—in a SaaS license agreement from the seller’s perspective. The goal was to reach a “market” position fair to both parties through a minimally viable redline: achieving the desired outcome with the fewest possible changes.
The contenders
Human experts: Five randomly selected redlines from attorneys with more than 12 years of experience and top-tier Big Law training.
Frontier models: ChatGPT 5.4, Claude Opus 4.6, and Gemini 3 Pro.
Each redline was evaluated across 10 data points, including waiver of indirect damages, scope of indemnification, and liability cap carve-outs. Rankings were determined using three criteria: Legal Precision, Minimalist Redline, and Speed to Closing (how closely the drafter thinks its redline aligns with the market baseline).
The Result
The final standings were:
No. 1: Attorney 2
No. 2: Attorney 3
No. 3: ChatGPT 5.4
No. 4: Attorney 1
No. 5: Attorney 5
No. 6: Gemini 3 Pro
No. 7: Attorney 4
No. 8: Claude Opus 4.6
The Key Takeaways
Top human still wins. The two highest-ranked redlines came from experienced attorneys who mastered the art of surgical editing—achieving strong protection with minimal disruption to the agreement.
The GPT-5.4 surprise. ChatGPT ranked third, outperforming three of the five human experts. For an out-of-the-box model with no specialized training data, that is a meaningful milestone for AI legal reasoning.
Claude’s “bloody redline.” Claude Opus 4.6 ranked last not because of legal inaccuracies, but because it attempted a near rewrite of the clauses. In a real negotiation, a replace-everything redline is a fast way to stall a deal.
No one is perfect. Neither experience nor compute power guarantees perfect work. Both human attorneys and frontier models introduced legal oversight and unnecessary edits.
The Why?
Out of curiosity, I asked each AI model to evaluate and rank all eight redlines without giving them the ten scoring datapoints. My assumption was that the model producing the best redline would also be able to rank it higher than the other model’s redlines.
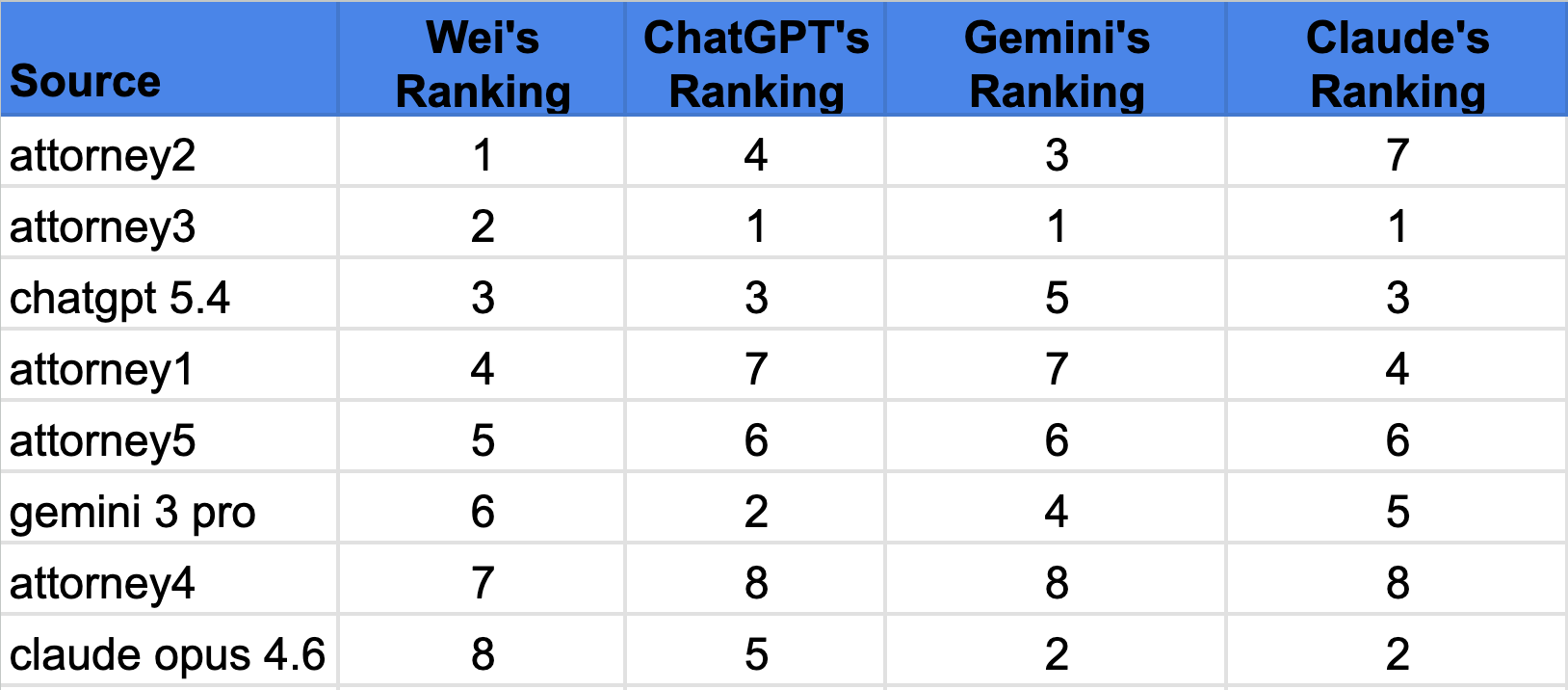
It turned out that ChatGPT 5.4, despite its superior redline, ranked Gemini’s redline higher than its own. Gemini 3 Pro, on the other hand, provided the most thoughtful reasoning for the ranking, though its own redline didn’t reflect the suggested changes. This seems to suggest that the models haven’t made coherent connections between the how and the why yet.
This highlights a deeper issue: high-quality redline training data are rare. Unlike contract classification or clause extraction, redlining is closer to an art form. Even experienced lawyers frequently disagree on the right edit, and what’s “market”.
And yet, despite the lack of training data, ChatGPT 5.4 still outperformed three experienced attorneys. If models are already performing at this level with almost no training data, the next twelve months should be fascinating.
–
To assess the AI performance for yourself, check out the 8 redlines and the 4 ranking files here.